Two papers have been accepted as oral presentations at the third Italian Conference on Computational Linguistics (CLiC-it 2016). The conference will be held in Napoli, at the Università Federico II, in December 5-6 2016.
- “KD Strikes Back: from Keyphrases to Labelled Domains Using External Knowledge Sources” by Giovanni Moretti, Rachele Sprugnoli, and Sara Tonelli
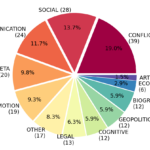
This paper presents L-KD, a tool that relies on available linguistic and knowledge resources to perform keyphrase clustering and labelling. The aim of L-KD is to help finding and tracing themes in English and Italian text data, represented by groups of keyphrases and associated domains. We perform an evaluation of the top-ranked domains using the 20 Newsgroup dataset, and we show that 8 domains out of 10 match with manually assigned labels. This confirms the good accuracy of this approach, which does not require supervision.
- “SIMPITIKI: a Simplification corpus for Italian extracted from Wikipedia” by Sara Tonelli, Alessio Palmero Aprosio and Francesca Saltori
In this work, we analyse whether Wikipedia can be used to leverage simplification pairs instead of Simple Wikipedia, which has proved unreliable for assessing automatic simplification systems, and is available only in English. We focus on sentence pairs in which the target sentence is the outcome of a Wikipedia edit marked as simplified, and manually annotate simplification phenomena following an existing scheme proposed for previous simplification corpora in Italian. The outcome of this work is the SIMPITIKI corpus, which we make freely available, with pairs of sentences extracted from Wikipedia edits and annotated with simplification types.
Website:



{kind=link}