The Content Types Dataset is a new resource aiming at promoting the analysis of texts as a composition of units with specific semantic and functional roles. By developing this dataset we also introduce a new NLP task for the automatic classification of Content Types. The identification of Content Types may improve the performance of more complex NLP tasks by targeting the portions of the documents that are more relevant.
The current release (February 2017) includes:
- the guidelines for the annotation of content types
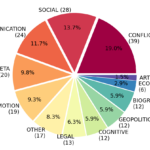
- the Content Type Dataset Version 1.0 including contemporary news and historical travel reports
- the data to replicate the experiments described in our EACL 2017 short paper (see below for the full reference)
All is available in our Github repository: https://github.com/dhfbk/content-types
This resource is licensed under a Creative Commons Attribution 4.0 International License.
If you use these datasets, please cite the following paper, where you can find more details on how the snippets were created:
Rachele Sprugnoli, Tommaso Caselli, Sara Tonelli and Giovanni Moretti. 2017. The Content Types Dataset: a New Resource to Explore Semantic and Functional Characteristics of Texts. In Proceedings of EACL 2017.
Contacts:
sprugnoli[AT]fbk.eu



{kind=link}