[English version below]
La popolarità dei social media ha portato a un notevole incremento della mole di dati testuali condivisi su Internet. A causa della loro natura spontanea e di veloce fruizione, questi dati presentano un gran numero di variazioni linguistiche, sia intenzionali (ad esempio slang, abbreviazioni, uso smodato di maiuscole, eccetera) che non intenzionali (ad esempio errori di battitura, accenti, eccetera). Questo pone notevoli problemi agli strumenti di natural language processing (NLP), la maggior parte dei quali sono stati originariamente progettati per elaborare testi “canonici”, il cui canone, per una coincidenza storica di disponibilità di risorse, coincide con il testo giornalistico. A differenza del testo giornalistico, o newswire, i contenuti generati dagli utenti sui social non vengono sottoposti a un processo di revisione, non devono aderire a norme redazionali, né sono prodotti in prevalenza da persone di alta classe sociale con tratti socio-demografici omogenei.
Un metodo per migliorare le prestazioni dei sistemi NLP sui testi provenienti dai social media è normalizzare il testo a livello lessicale, e quindi renderlo più simile ai dati per i quali i sistemi NLP sono stati inizialmente progettati (e addestrati). Questo task prende il nome di normalizzazione lessicale (lexical normalization), ed è formalmente definito come “il processo di conversione di un testo nella sua forma standard, parola per parola, incluse sostituzioni uno a molti (1-n) e molti a uno (n-1)”.
Nonostante la dimostrata utilità della normalizzazione lessicale per diversi task a valle (ad esempio part-of-speech tagging, parsing, machine translation, eccetera), gli sforzi della ricerca su questo tema risultano in gran parte frammentati: i lavori ad oggi si sono principalmente focalizzati su una singola lingua, si basano su metriche di valutazione differenti e fanno diverse assunzioni sugli elementi lessicali da normalizzare. Tutto ciò rende estremamente difficile confrontare i sistemi di normalizzazione esistenti e nuovi, ed estenderli a più varietà linguistiche.
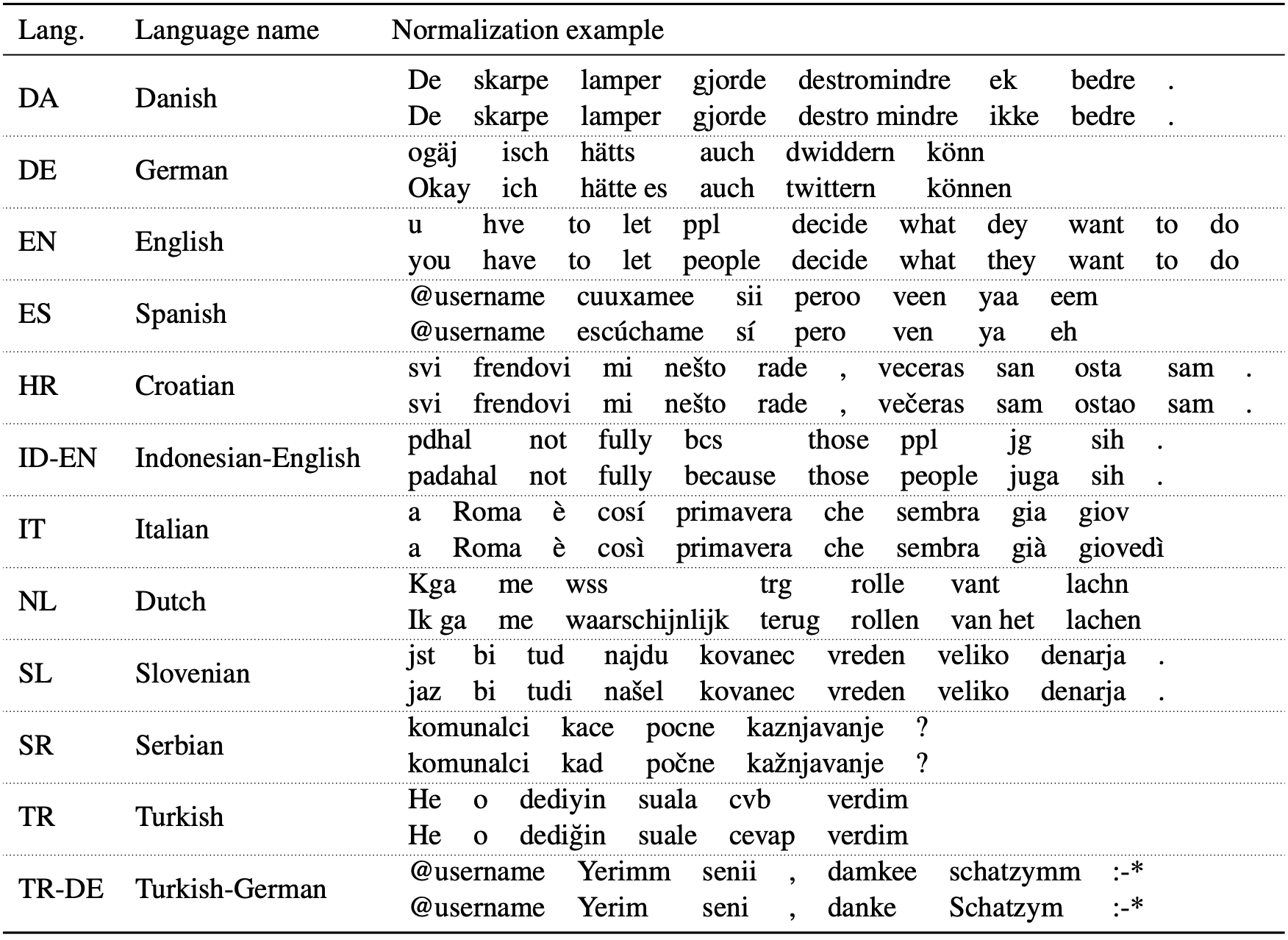
Nel tentativo di supportare una maggiore riproducibilità, una più ampia varietà linguistica e un metodo di valutazione standard per la normalizzazione lessicale multilingua, abbiamo introdotto il benchmark MultiLexNorm e organizzato una shared task sul tema. MultiLexNorm unifica e armonizza 12 dataset per la normalizzazione lessicale in 10 lingue (croato, danese, inglese, italiano, olandese, serbo, sloveno, spagnolo, tedesco e turco) e 2 coppie di lingue a commutazione di codice (indonesiano-inglese e turco-tedesco). Un esempio di normalizzazione lessicale per ogni lingua (o coppia di lingue) preso da MultiLexNorm è presentato di seguito.
Per valutare la bontà del metodo di normalizzazione lessicale proposto da ogni partecipante, ogni sistema è stato sottoposto a una valutazione intrinseca sulla base della media in Error Reduction Rate (ERR) nelle varie lingue ed è stato messo a confronto con due baseline e con il sistema di normalizzazione allo stato dell’arte MoNoise. Inoltre, per valutare con precisione l’effetto della normalizzazione, ogni metodo è stato testato estrinsecamente (con metriche che considerano i casi di normalizzazione 1-n e n-1) nei task di part-of-speech tagging e dependency parsing in seguito alla normalizzazione lessicale.
La shared task, ospitata al 7th Workshop on Noisy User-generated Text (W-NUT) nel contesto della conferenza internazionale Empirical Methods in Natural Language Processing (EMNLP), ha attirato 18 submission da 9 team di ricercatori. I risultati della competizione dimostrano come il precedente stato dell’arte sia ormai ampiamente superato da una soluzione di normalizzazione word-by-word basata su ByT5 e due step di fine-tuning (team ÚFAL), e da una soluzione che consiste in una preliminare identificazione della tipologia di sostituzione da effettuare usando BERT, seguita dalla normalizzazione effettiva usando un metodo di traduzione automatica a livello di carattere (team HEL-LJU). Questi metodi mostrano un’influenza positiva sia su part-of-speech tagging (fino a +1,54 a-POS) che su dependency parsing (fino a 1,72 a-LAS e 0,85 a-UAS). Tuttavia, osserviamo ancora un divario prestazionale importante rispetto ai testi canonici. Si rimanda allo shared task paper [1] per una descrizione di tutti gli approcci proposti, molto vari e d’ispirazione per lavori futuri.
Ci auguriamo che il benchmark proposto possa stimolare rinnovato interesse sulla normalizzazione lessicale multilingua e che possa portare a confronti più trasparenti ed equi. Al di là dell’utilità per molteplici task a valle, crediamo inoltre che i metodi per la normalizzazione lessicale possano essere d’ispirazione per lo studio del significato sociale della variazione linguistica, potendo essere reimpiegati per l’analisi di forme lessicali non-standard. Tutte le submission, le baseline e gli script di valutazione sono disponibili nel repository della shared task MultiLexNorm.
Nel caso foste interessati a saperne di più, ci trovate al 7th Workshop on Noisy User-generated Text (W-NUT) ad EMNLP l’11 novembre 2021 alle 7:50 (GMT+1)! 😉
English version
The rise of social media has led to a tremendous increase in the amount of data shared over the Internet. But because of its spontaneous nature and fast consumption, the data naturally abounds with numerous language variations, both intended (e.g., slang, abbreviations, non-standard capitalization) and unintended ones (e.g., typos, diacritics). This, in turn, poses considerable problems for existing natural language processing (NLP) tools, most of which were originally designed to process “canonical” texts, a canon that for an historical coincidence of availability of resources mostly matches with the newswire. Differently from the newswire text type, user-generated content on social media does not undergo a revision process, does not need to adhere to editorial norms, nor is it mostly written by high class people with homogeneous sociodemographic traits.
One way to improve the performance of NLP systems on social media content is to normalize text at a lexical level, and thus make it more similar to the data the NLP systems were initially designed for (and trained on). This task is known as lexical normalization, and it is formally defined as “the task of transforming an utterance into its standard form, word by word, including both one-to-many (1-n) and many-to-one (n-1) replacements”.
Although lexical normalization has been shown to boost many downstream tasks (e.g., part-of-speech tagging, parsing, machine translation, inter alia), research efforts on this topic are largely fragmented: existing work focused mostly on one language, relies on different evaluation metrics, or makes different assumptions regarding the items to be normalized. All this makes it extremely hard to compare existing and new normalization systems, as well as to extend them to other linguistic varieties.
In an attempt to achieve greater reproducibility, linguistic variety, and a standardized evaluation method for multilingual lexical normalization, we introduced the MultiLexNorm benchmark and a corresponding shared task. The MultiLexNorm benchmark collects and homogenizes datasets for lexical normalization for 10 languages (Danish, German, English, Spanish, Croatian, Italian, Dutch, Slovenian, Serbian, Turkish) and 2 code-switched language pairs (Indonesian-English and Turkish-German). An example of lexical normalization for each language (or code-switched language pair) taken from MultiLexNorm is shown in the following.
To assess the lexical normalization methods proposed by participants, each system has been evaluated intrinsically using the average in Error Reduction Rate (ERR) across languages, and it has been compared to two baselines and to the state-of-the-art normalization system MoNoise. Further, to precisely measure the effect of text normalization, each method has been tested extrinsically (with alignment-aware metrics that consider 1-n and n-1 normalization instances) on part-of-speech tagging and dependency parsing tasks after normalization.
The shared task, hosted at the 7th Workshop on Noisy User-generated Text (W-NUT) together with the international conference Empirical Methods in Natural Language Processing (EMNLP), attracted 18 submissions by 9 participants. The competition results show that the previous state-of-the-art system has been outperformed by a large margin by a word-by-word normalization solution based on ByT5 and two fine-tuning steps (ÚFAL team, winner of the shared task), and by a solution that consists of a preliminary identification of the substitution type to perform using BERT, followed by the actual normalization using a character-level statistical machine translation method (HEL-LJU team). Those methods show a positive influence on both part-of-speech tagging (up to +1.54 a-POS) and dependency parsing (up to 1.72 a-LAS and 0.85 a-UAS). However, there is still a performance gap compared to the performance levels observed on canonical data. We refer to the shared task paper [1] for a description of all proposed approaches, very varied and inspirational for future work.
We hope that the proposed benchmark will lead to more research in multilingual lexical normalization, and more transparent and fairer comparisons. Besides the usefulness for many downstream tasks, we believe lexical normalization methods can be of inspiration for studying the social meaning based on linguistic variation, since those approaches can be repurposed for analyzing non-standard lexical forms. All submissions, baselines, and evaluation scripts are available in the MultiLexNorm shared task repository.
If you are interested in knowing more, you can find us at the 7th Workshop on Noisy User-generated Text (W-NUT) at EMNLP on November 11, 2021, at 7:50 AM (GMT+1)! 😉
References
[1] Rob van der Goot, Alan Ramponi, Arkaitz Zubiaga, Barbara Plank, Benjamin Muller, Iñaki San Vicente Roncal, Nikola Ljubešić, Özlem Çetinoğlu, Rahmad Mahendra, Talha Çolakoğlu, Timothy Baldwin, Tommaso Caselli, and Wladimir Sidorenko. 2021. MultiLexNorm: A shared task on multilingual lexical normalization. In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.




{kind=link}