The paper “Automatically Evaluating the Quality of Textual Descriptions in Cultural Heritage Records” authored by Matteo Lorenzini, Marco Rospocher (University of Verona) and Sara Tonelli has been accepted for publication in the International Journal on Digital Libraries.


Abstract
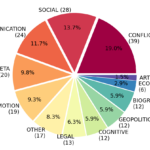
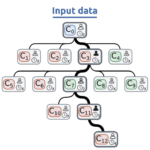
Metadata are fundamental for the indexing, browsing and retrieval of cultural heritage resources in repositories, digital libraries and catalogues. In order to be effectively exploited, metadata information has to meet some quality standards, typically defined in the collection usage guidelines. As manually checking the quality of metadata in a repository may not be affordable, especially in large collections, in this paper we specifically address the problem of automatically assessing the quality of metadata, focusing in particular on textual descriptions of cultural heritage items. We describe a novel approach based on machine learning that tackles this problem by framing it as a binary text classification task aimed at evaluating the accuracy of textual descriptions. We report our assessment of different classifiers using a new dataset that we developed, containing more than 100K descriptions. The dataset was extracted from different collections and domains from the Italian digital library “Cultura Italia” and was annotated with accuracy information in terms of compliance with the cataloguing guidelines. The results empirically confirm that our proposed approach can effectively support curators (F1 ∼0.85) in assessing the quality of the textual descriptions of the records.
Link to github: https://github.com/matteoLorenzini/description_quality



{kind=link}